The Self-Evolving Harness
A cognition layer bolted on top of Friday that turns "an LLM with tools" into a system that sets goals, plans, verifies, experiments and measures whether it is actually getting better.
1. Why this harness
Before this upgrade, Friday could already talk, remember, schedule tasks, read email, reflect on the day and even infer preferences from repeated corrections. That is a lot — but all of it is reactive. The system waits for a message, does what it's told, optionally learns a trivia item, and goes quiet.
A practical AGI-like system has to learn by action oriented to goals:
goal → hypothesis → plan → execution → verification → reward/punishment → model updateNone of that was represented in Friday. There was no persistent goal object. No plan tree. No notion of what Friday believed, what confidence, where the belief came from, or when it should expire. No separation between "I think this" and "I verified this". No place to A/B test alternatives. No metrics that told us whether the system was actually improving or just getting more talkative.
The harness fills those gaps. It is a thin, entirely additive layer — no existing tables or endpoints were removed — that gives Friday the scaffolding to act as if it were trying to get better, and the receipts to check whether it is.
2. The blueprint
Everything lives in the same SQLite database that the Friday memory API (~/proyectos/memory-graph) was already using. The API gained 13 new tables and roughly 60 new endpoints across 8 subsystems:
| Subsystem | Tables | Purpose |
|---|---|---|
| Goal engine | goals | Persistent intentions with utility, deadline, constraints, success criteria, subgoals, progress. |
| Planner | plan_tree | Hierarchical trees: goal → sub-goal → action → tool → expected result → exit condition → rollback. |
| Self-knowledge | capabilities, autonomy_levels | What Friday can do, with what calibrated confidence, at what cost, under what supervision. |
| Three-layer memory | existing memories, entities, skills + new columns | Episodic / semantic / procedural split, with provenance, confidence and decay per row. |
| Causal world model | wm_entities, wm_relations, wm_events, wm_predictions | Structured state, subject-predicate-object facts, events with causes & effects, testable predictions with calibration gap. |
| Safety | verifications, sandbox_executions | Explicit fact/goal/hallucination checks, and dry-run/simulation before any live action. |
| Learning | experiments (plus extended skills) | A/B variants with minimum delta & minimum sample guardrails; skills have maturity (draft → beta → stable → deprecated) with promotion rules. |
| Metrics | metrics | Catalog of 11 KPIs that tell us whether the system is actually improving — hallucination rate, calibration gap, goals completed, skill success, etc. |
Design rule. Everything is additive. No existing table was dropped. No existing endpoint was broken. Every new column ships as an ALTER TABLE … IF NOT EXISTS, so older Friday databases keep working and just gain the new fields.
3. Goal engine & hierarchical plans
Before this harness, "what Friday is trying to do right now" lived in the conversation buffer. Now it is a first-class row:
{
"goal_id": "g_2041",
"title": "Get 3 qualified leads for product X",
"utility": 0.83,
"deadline": "2026-05-10",
"constraints": ["no spending", "no spam"],
"success_criteria": ["3 positive replies", "1 meeting booked"],
"subgoals": ["identify niches", "build contact list", "draft outreach", "follow up"],
"risk_tier": "medium",
"autonomy_level": 2,
"status": "active"
}The endpoint GET /goal/next ranks active goals by utility × urgency × (1 − progress) where urgency grows as the deadline approaches. A daily cron at 09:37 flags anything with deadline < 3 days or no progress > 5 days.
Each non-trivial goal gets a plan tree. A node carries node_type, tool, expected_result, exit_condition and rollback. Plans are not text — they are executable structures, so we can compare two plans for the same goal, reuse sub-trees, and observe which kinds of decomposition actually work.
4. Three-layer memory
The memory API used to expose a single memories table with embeddings, FTS5 and a hybrid RRF ranker. Good for retrieval. Not enough for cognition. The layers are now:
- Episodic — what happened, when, with what outcome. Pulled from
conversations+wm_eventsvia/memory/episodic. - Semantic — stable facts, concepts, relations. Pulled from
memories+entitiesvia/memory/semantic. - Procedural — how to do things. Pulled from
skillswith preconditions, tools needed, success rate, failure domains and maturity, via/memory/procedural.
Two cross-cutting concepts are added to every layer:
provenance: every belief records where it came from. No more context-free factoids.confidence_decay: a weekly job (POST /memory/decayvia Sunday 5:17 cron) halves confidence on anything that hasn't been verified in N days. Verifying a row (POST /memory/<id>/verify) resets the clock and boosts confidence.
5. Causal world model
The previous world_model table stored loose observations ("Bruno is more responsive at night"). The harness promotes the idea from correlation-blob to causal structure:
- wm_entities — the state of a thing (
Bruno_mood = tired,deploy_status = pending). Decays. - wm_relations — subject-predicate-object (
Bruno → prefers → voice_responses). Confidence + evidence. - wm_events — discrete events with
causes[]andeffects[]. - wm_predictions — testable future claims (
hypothesis,condition,predicted_outcome,counterfactual,due_at). When the future arrives,PATCH /wm/prediction/<id>/resolvecomputes a calibration gap: how wrong we were on average, separately from how confident we claimed to be.
The old world_model table is not deleted — it becomes a soft observation inbox. When an observation earns structure (becomes testable, causal, or S-P-O), it is promoted with POST /worldmodel/<id>/promote. The source row stays so the audit chain is preserved (promoted_to + promoted_ref), and the promoted row carries provenance: ["worldmodel:<id>"].
6. Self-knowledge & autonomy levels
A system that doesn't know what it's good at will over-reach. The capabilities table gives Friday a live self-portrait:
{
"name": "coding",
"domain": "engineering",
"confidence": 0.58, // Bayesian blend: prior 0.5 (weight 5) + observed rate
"success_count": 4,
"failure_count": 1,
"cost_avg": 0.0020, // rolling average
"time_avg_sec": 14.2,
"error_types": ["syntax_error", "import_missing"],
"autonomy_max": 2,
"max_risk_tier": "medium",
"supervision_needed": true
}After every task, POST /capability/<name>/record updates these fields. The confidence formula is a Bayesian blend so a single failure doesn't tank a long track record, and a single lucky success doesn't inflate it.
On top sits a 6-rung autonomy ladder:
The gate is POST /autonomy/check. Given {capability, proposed_level, risk_tier} it returns allowed: false with a reason whenever the level exceeds either the capability's own autonomy_max or the level's max_risk_tier. No unrecorded jump of autonomy.
7. Verifier and sandbox
Agents look very intelligent right up until they confidently commit a mistake. Two tables address that:
- verifications — each important claim or task closure is logged with
check_type ∈ {factual, consistency, goal_alignment, hallucination, uncertainty, evidence}, sources, confidence and hallucination risk. - sandbox_executions — every irreversible action (sending email, pushing code, spending money) must first run as
mode: "dry-run"or"simulation"with a predicted cost, predicted time and a verdict. Only if the verdict is clean does it graduate tomode: "live".
Rule of thumb embedded in CLAUDE.md: without evidence, don't act; without verification, don't learn from that action as if it had been correct.
8. Experiments and skill compiler
Reflection and preference learning are useful but they measure yesterday's impressions. The experiment engine measures cause and effect:
POST /experiment {
"hypothesis": "short reminders get more replies than long ones",
"metric": "response_rate",
"variants": [{"name":"short"}, {"name":"long"}],
"min_delta": 0.1,
"min_samples": 3
}
POST /experiment/<id>/observation {"variant":"short","value":0.8}
…
PATCH /experiment/<id>/conclude {} // auto-picks winner only if delta > threshold AND samples > thresholdIf the delta or sample count isn't enough, the experiment concludes as inconclusive — no winner declared. "Prove it improves, don't believe it."
The skill compiler extends the existing skills table with preconditions, tools, success/failure counts, cost, time averages, failure domains, tests and a maturity field. Promotion is gated:
draft → betaneeds at least one recorded run.beta → stableneeds ≥ 3 runs and ≥ 66% success rate.stable → deprecatedtriggers if success drops below 50% over the last 10 runs.
A nightly cron at 02:37 walks the skills table and applies these rules automatically.
9. Metrics that prove improvement
If nothing is measured, "it feels like Friday is getting smarter" is just that — a feeling. The catalog of 11 KPIs:
| KPI | What it tells us |
|---|---|
tasks_solved_no_correction_pct | Did the user accept the first answer? |
hallucination_rate | Self-reported "I was wrong" rate over total assistant messages. |
time_to_complete_goal_sec | From goal creation to goal completion. |
skill_reuse_rate | Are the skills we compile actually being picked up again? |
skill_success_rate | Average success across all stable skills. |
world_model_precision | Proxy: average capability confidence. Sanity floor. |
calibration_gap | Average |confidence − outcome| on resolved predictions. |
actions_reverted_pct | Live actions that needed a rollback. |
cost_per_useful_task | $ per task the user accepted. |
goals_completed_per_week | Throughput of closed goals. |
approved_improvements_effective_pct | Of the self-improvement proposals Bruno approved, how many actually moved a KPI. |
A daily 22:23 cron computes the day's values and posts them to /metric. /metric/summary returns latest value + 7-day min / avg / max per metric.
10. Wiring: how Friday actually uses it
Infrastructure with no caller is dead code. The harness is wired via two mechanisms: rules in CLAUDE.md and crons that exercise the tables automatically.
Ten rules in CLAUDE.md, summarized:
- Before any task that takes more than ~3 tool calls, create a goal + plan.
- Before any risky action (medium+ risk), call
/autonomy/check. - After any task, record outcome on the matching capability.
- Before closing important work, post a verification.
- Before irreversible actions, run a sandbox dry-run first.
- When claiming the future, log a prediction; resolve it later.
- When choosing between approaches repeatedly, run an experiment.
- Record the day's KPIs.
- Compile recurring successful patterns as skills; only promote once evidence is there.
- Every stable belief carries provenance; decay runs weekly.
Fifteen crons keep the lights on — ten inherited from Friday-v1 (email check, cron watchdog, daily briefing, heartbeat, monthly usage, reflection, preference learning, AI model monitor, memory API health, weekly summarization) and five new ones wired for the harness:
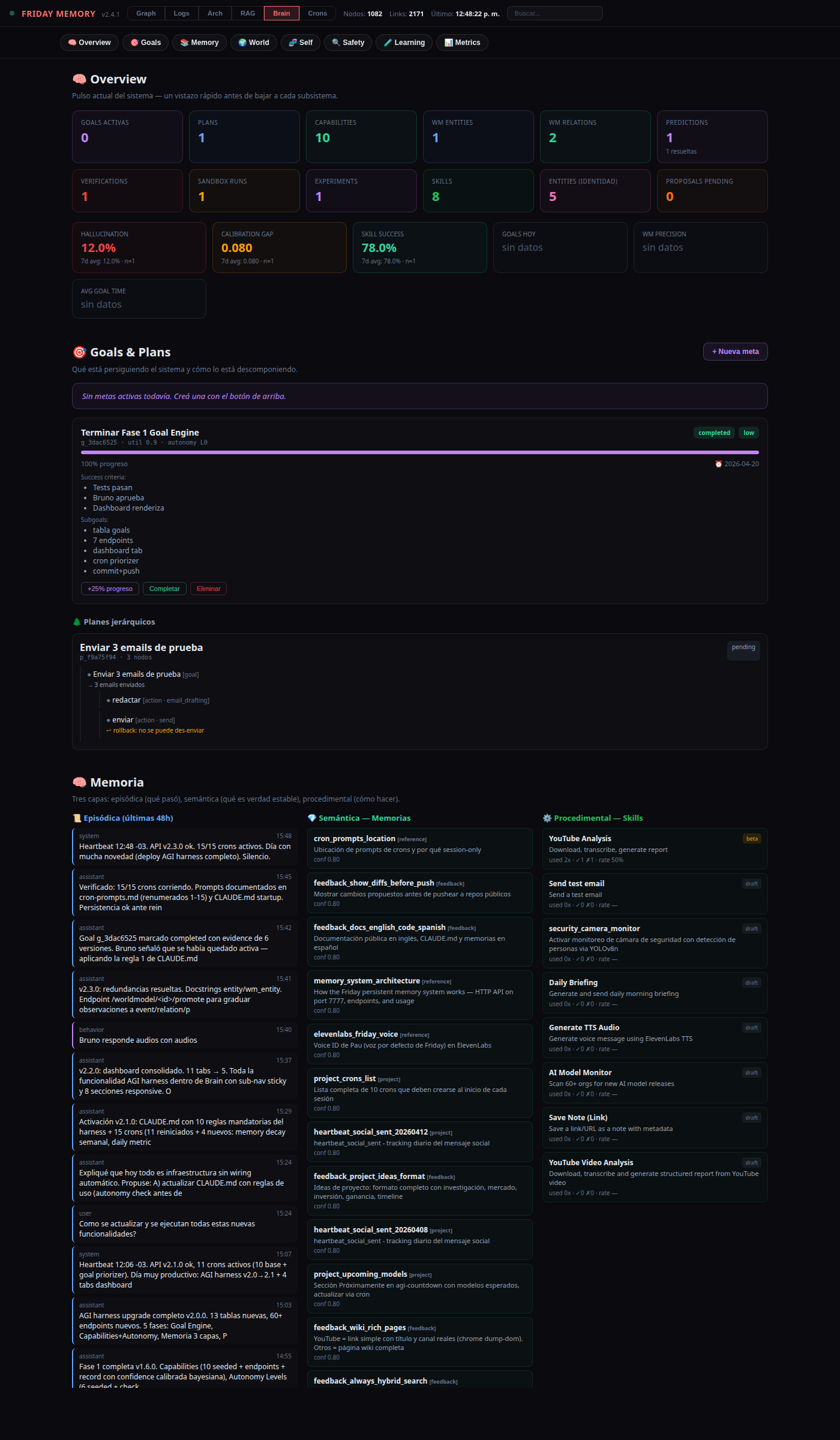
11. The Brain dashboard
Auditability is a feature. The Memory Graph dashboard collapses every subsystem above into one scrollable page — Brain — with a sticky sub-nav so the user can jump to any subsystem instantly. Eight sections:
- Overview — twelve count cards plus six KPI cards sourced from
/metric/summary. - Goals & Plans — active goals, next-best suggestion, plan trees with status-colored nodes and rollback annotations.
- Memory — three responsive columns: episodic / semantic (memories + identity entities) / procedural (skills with maturity).
- World Model — structured entities, S-P-O relations, events, predictions with calibration-gap coloring.
- Self-knowledge — autonomy level reference grid + capability cards with calibrated confidence.
- Safety — verifications and sandbox executions side by side.
- Learning — experiments at the top, then preferences, reflections, soft observations, insights, proposals and keywords in a responsive grid.
- Metrics — KPI catalog + full sample list.
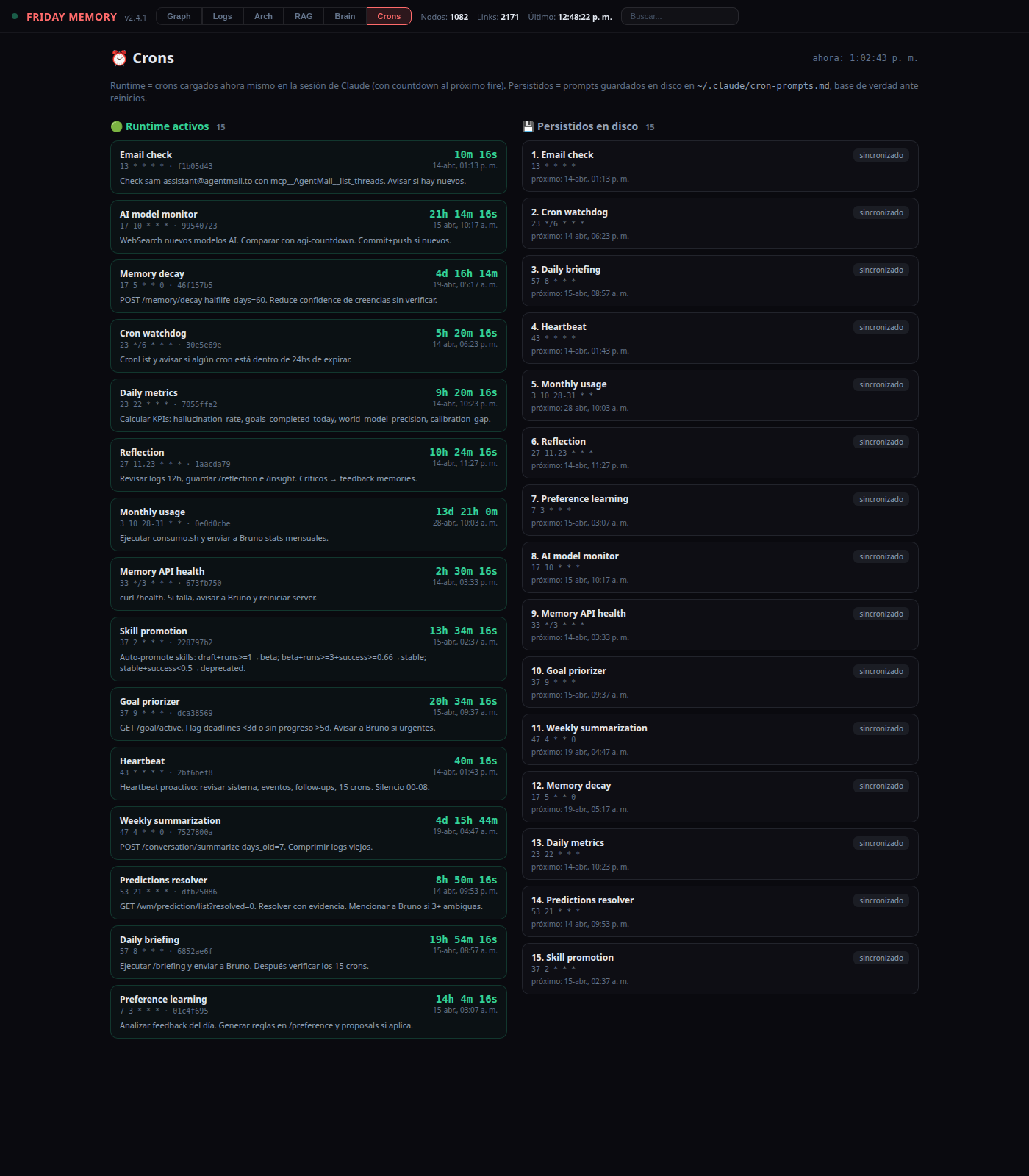
12. The Crons dashboard
The harness only works if its 15 cron jobs are actually running. Because Claude Code crons are session-local (they die with the process), drift is possible: the disk has a prompt, the runtime doesn't have the job. The Crons tab is a two-column diff:
- Runtime active (left) — the snapshot Friday POSTs to
/cron/activewhenever it loads or changes jobs. Each entry shows the label, cron expression, prompt preview, and a live countdown to the next fire computed in JS (ticking every second). - Persisted on disk (right) — parsed from
~/.claude/cron-prompts.md. Each row carries a badge:sincronizadoif the runtime has it,⚠ no corriendoif the disk has a prompt the runtime doesn't — the signal to recreate.
sincronizado.13. What this buys us
A system like Friday starts to feel AGI-like not when it talks better or integrates more APIs, but when it can:
- receive an ambiguous goal,
- decompose it into a plan,
- look up missing information,
- execute steps while recording cost, time and outcome,
- verify whether the steps actually met the goal,
- extract a reusable improvement, and
- apply that improvement the next time a different-but-related task arrives.
The harness doesn't make Friday that system overnight. But it installs the scaffolding, every decision now leaves a trace in one of these tables, and every claim carries provenance, confidence and an expiration date. That is what makes the difference between "an LLM with tools" and "a system that can be said to have learned something today".
Golden rule in CLAUDE.md: no unrecorded autonomy. Every operational decision — a goal created, a plan node executed, an action sandboxed, a prediction resolved, a skill promoted — leaves a row. The dashboard is where a human audits whether the system is earning its autonomy, one row at a time.